


How Images are turned Into Arrays
How Images are turned into arrays in Computer Vision


“The world of the future will be an even more demanding struggle against the limitations of our intelligence, not a comfortable hammock in which we can lie down to be waited upon by our robot slaves.” ― Norbert Wiener
We've all probably used our phone's Face Recognition feature to unlock it. In this article, we are going to understand how our phones turn our images into arrays which can then be processed by computers.

What is Computer Vision?
To get a clearer picture of how Images are turned into arrays in Machine Learning let us understand what Computer Vision is.
According to Wikipedia, Computer vision is an interdisciplinary scientific field that deals with how computers can gain high-level understanding from digital images or videos.
In simple words, It is a field of AI which deals with how computers see.
How Images are turned Into Arrays
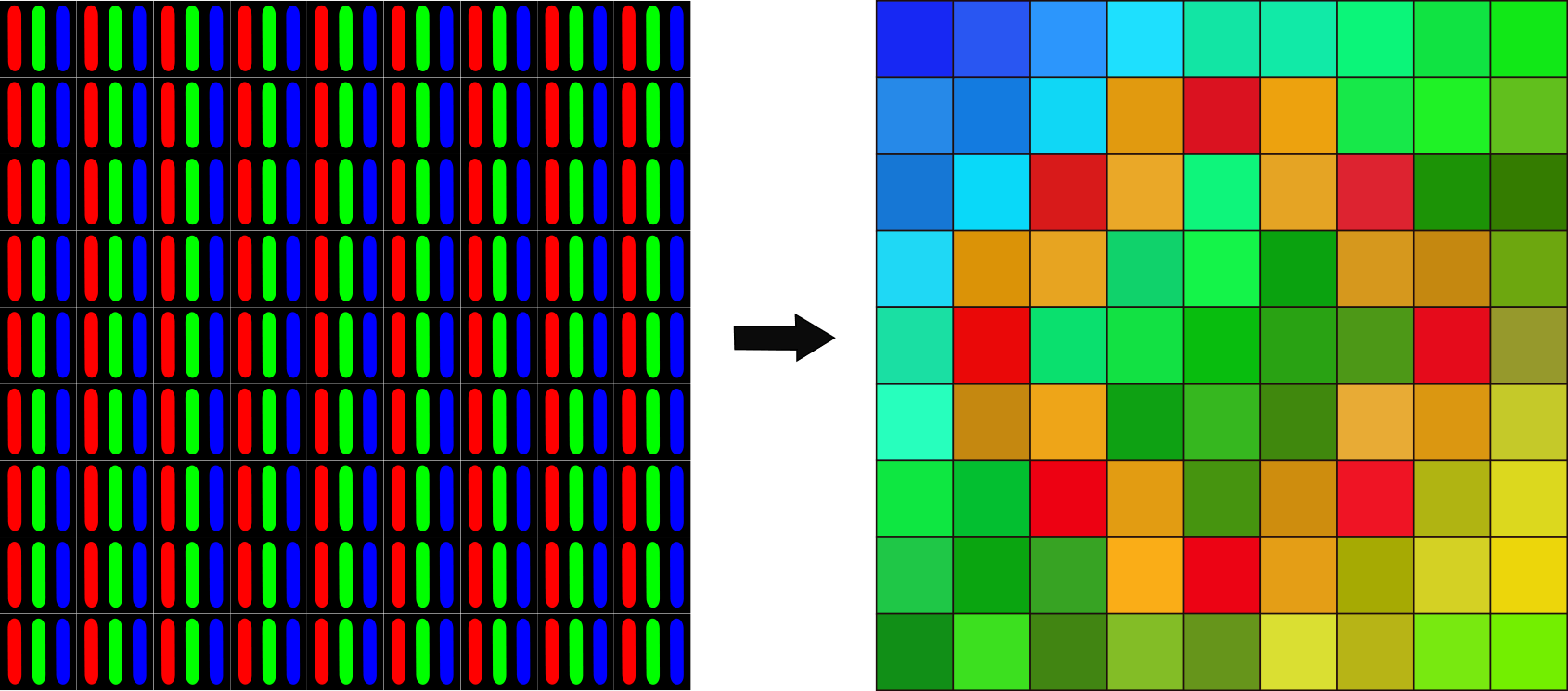 To begin with, a camera records the amount of light reflected in it from the surfaces of objects(data) in a 3D scene/environment.
To begin with, a camera records the amount of light reflected in it from the surfaces of objects(data) in a 3D scene/environment.
This data is then transmitted to electrical signals which vary proportionately to the intensity of reflected light. A convertor then changes(converts) the analog electrical signal into digital information for the computer by sampling the signal at regular intervals and translating each electrical signal into a number representing a position on a range of brightness/intensity on a GrayScale.
The numbers then form a two-dimensional grid called a gray level array, each value in the array constitutes a pixel (picture element) of the digitized image. Computer Vision systems commonly use grayscale with values ranging from Zero-255, Zero represents the darkest areas of the image while 255 represents the lightest parts of the image.
Color images make use of separate measurements each for the amount of Red, Green, and Blue reflected from the image/scene. The measurements are then translated into three separate arrays of brightness values, each varying from Zero to 255. This is why Color Images take more time to process than black and white images.
How Images are turned Into Arrays(Broken Down Version)
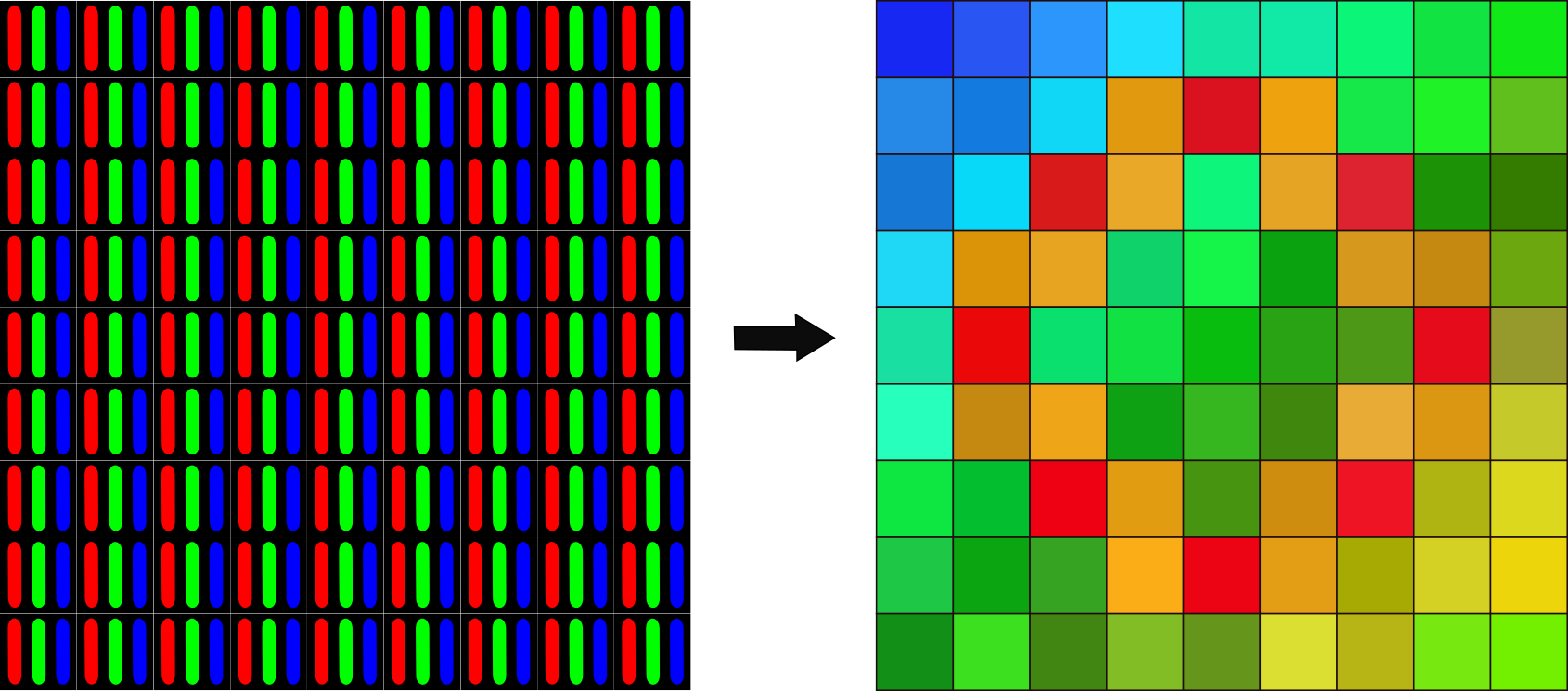 When a camera records a live scene for a computer Vision neural network, it records the amount of light reflected from the surface of the object in a 3d scene/environment.
When a camera records a live scene for a computer Vision neural network, it records the amount of light reflected from the surface of the object in a 3d scene/environment.
This reflection data is then transmitted as electrical signals which increase or decrease based on the intensity of the light reflected from the body of the object.
A convertor then changes the electrical signals into digital information for the computer by continuously going through the entire surface of the object in question, each electrical signal is then transmitted into a number representing a position of intensity(either bright or dark), the number in question is graded according to something called the grayscale.
The grayscale is mostly made up of numbers from zero to 255 , it provides number ranges based on the intensity of light reflection gotten from the object with zero as the darkest point and 255 being the lightest point.
These numbers then form a two-dimensional grid array with each digit in the array representing a pixel(Picture Element) in the Object/Picture.
In simple words, the two-dimensional array represents the image and the numbers represent the pixel.
Colored pictures require the creation of 3 different arrays for brightness values each containing digital info on Red, Green, and Blue wavelengths gotten from the object reflection. This is why Colored Pictures/Objects take way more time to process than Black and White Images.